Dimensionality Reduction & Feature Extraction Techniques in Python: Part one
TLDR: you can apply functions on data to make it easier to handle, to see the code click here
Over the past 30 years, the amount of data that has been produced has grown exponentially. When there is a large set of multidimensional data, the chance that some data might overlap can occur. In this post, we will be talking about Dimensional Reduction and Feature Extraction. These are needed in Machine Learning/ Deep Learning to allow the Neural Networks an easier way to map the data.
Dimensional reduction is typically choosing a basis or mathematical representation within which you can describe most but not all of the variance within your data, thereby retaining the relevant information, while reducing the amount of information necessary to represent it. Feature Selection is hand-selecting features that are highly discriminating. This has a lot more to do with feature engineering than analysis and requires significantly more work on the part of the data scientist. It requires an understanding of what aspects of your dataset are important in whatever predictions you’re making, and which aren’t. Feature extraction usually involves generating new features which are composites of existing features
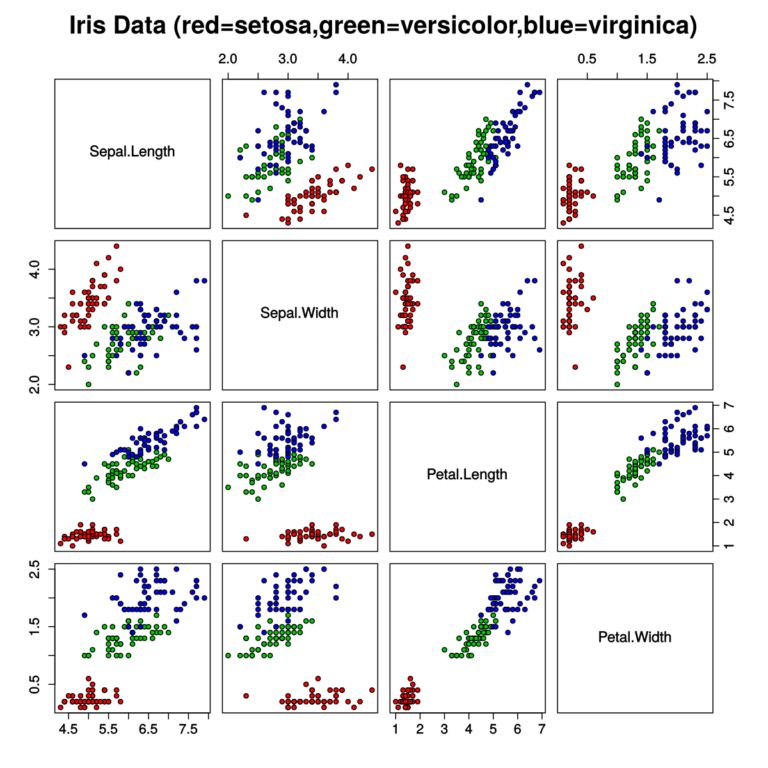
We will be looking at the iris dataset, which is relatively small but has four dimensions.If you where to take the raw data and try to parse it, it would be visualized as such:
Default visualization of the 4 columns for the Iris dataset
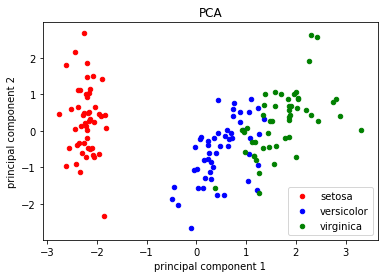
Now if you were to look at this and try to determine how to classify a new data point that might prove difficult. This is with only four features, imagine going up to 10 features or even hundreds? Because of this, we need to have Dimensionality Reduction and Feature Extraction. If we took the data and applied a Principle Component Analysis to the data we can reduce the dimensions to two! Now we have data that look like this:
Applying the Principal Component Analysis (PCA) to the Dataset
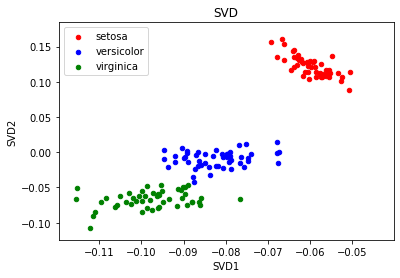
By using mathematics we can reduce the number of features and make it easier to visualize and separate the data. However, there are different ways to reduce the features of a dataset! The next one we will look at is the Single Value Decomposition (SVD). Now we can have data that looks like this:
Looking at these two newly formed datasets that reduce the dimensionality of the original dataset we can see that it would be much easier for a neural network to classify points based on these reduced dimensions compared to the original. It is always preferred when working with data to reduce the dimensions and make it easier to classify or visualize the data. Using these methods we can do exactly that!