Introduction to Parallel Programming
Why GPUS?
High-performance computing (HPC) has become an inexhaustible tool to solve resource-intensive problems. Using HPC we can process larger amounts of information in the same, or less, time! Learning new HPC techniques serves as an essential tool in the data analysis world.
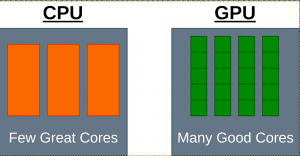
One example of HPC programming is GPU (Graphical Processing Unit) programming. Currently, most people run their code on CPUs (Central Processing Unit) processor, but as we will show, if you want to a large amount of process data quickly, a GPU will be better.
Without looking at either a CPU or a GPU we will first focusing on the processor inside of them. Over the past few decades, the speed of processors has exponentially increased; in turn, its size has decreased.
As the size has decreased the overall machine has decreased. This can be shown by the size of the IBM computers used to put men on the moon (took up whole rooms), to the transition of personal desktops (huge and bulky), then laptops (slimmer), and now mobile phones (fits in your hand). Over time the processors got smaller and the processing speed got better. To the average person, this is amazing, smaller faster computers, but to the people developing the hardware, they are struggling to keep up with their own growth.
Designing the hardware for computers can be summed up in one sentence: “make them process data faster”, sadly this is easier said than done. Three traditional ways hardware designers made their computers run faster was by increasing the clock speed/clock cycle, or adding more processors.
The clock speed/cycle are elements of the Processing Unit (PU) on a computer. The clock speed is the speed of the processor – the amount of time between two pulses.
If we use the analogy of vehicular transportation; imagine that a normal PU is a car. It can transport 4 people at 60 MPH to a final destination. A sports car on the other hand can carry 4 people at 100 mph allowing people to reach their destination quicker. A pickup truck can carry 13 people, but moves slower, on the end of this extreme is a semi truck which moves about a little slower than a pickup truck but carries much more stuff.
The analogy to a PU would be as follows:
- Sports Car: would have the same number of Cores, but a higher clock speed, uses a little more power
- Pickup truck: Has more cores at an a low clock speed, uses more power
- Semi-Truck: More Cores, lower clock speed, uses a lot more power
Depending on what you want to do determines what vehicle you would you. For daily stuff a normal car is fine, but if you are transmitting a lot of data you wouldnt use a sports car. The same would be true for using a semi truck to send a small package.
Going back to the processors, we have previously stated that they where being made to be smaller, use less power and faster. In doing so, however, we kept increasing the clock speed and clock cycle. If we increase the size and pressure of anything in a small space, it will get hotter.
This is what happened to the individual processors inside CPUs. Now we are are at a standstill for how fast and how much data we can process on a CPU, but science does not stop. Since we hit this new problem the new question to ask our self is… “What can we do to process more data quicker?”.
We can build a lot of good processors instead of a few amazing ones! Doing this will allow us to process data in parallel, distribute how much work a single processor does, and also distributing the head. Surprisingly enough something like that already exists.
GPUs! While a CPU has a more complex control structure, great flexibility, and performance, it uses a lot of power. On the other hand, GPUs have a simple control structure, more hardware, and better power usage. The only downside is that GPUs have a more restrictive programming model, but since a hardware developer is looking at designing it that is a problem for the software engineers to figure out.
A modern GPU has 100+ processors, 1000+ threads and 1000+ arithmetic operations (ALU).